- Ollama(オラマ)とは
Ollama(オラマ)は、ローカル環境で大規模言語モデル(LLM)を実行できるツールです。
MacやWindows、Linuxに対応しており、インターネットに依存せずChatGPTやQwenなどのモデルを動かせるのが最大の特徴です。
名前の由来は英語圏の発音に基づき「オラマ」と読みます。Ollamaでは、
ollama pull モデル名のようなコマンドでモデルをダウンロードし、その後ollama run モデル名やollama serveで実行できます。
対応モデルはLLaMA、Mistral、Qwen、Gemmaなど多数。開発者は自由にモデルを追加・管理可能です。
Ollamaを使うメリット
オフライン利用が可能
初回ダウンロード後はネット接続不要で動作するため、セキュリティ要件が厳しい環境でも安心して利用できます。
API利用料が不要
ChatGPTやClaudeなどのクラウドサービスと違い、従量課金が発生しません。ローカルPCの性能さえあれば使い放題です。
モデル選択の自由度が高い
QwenやLLaMA、Mistral、Gemmaなど様々なオープンソースモデルを手軽に試せます。サイズや用途に応じた柔軟な選択が可能です。
カスタマイズ可能
モデルファイルや設定を調整することで、自分の用途やリソースに合わせて最適化できます。
Ollamaを使うデメリット
PCスペックに依存する
大規模モデルほどメモリやVRAMを必要とし、低スペック環境では動作が遅くなるか実行できません。
ストレージ消費が大きい
1モデルで数GB〜数十GBを占有する場合があり、複数モデルを試すなら大容量SSDが必須です。
導入・管理にやや慣れが必要
コマンドライン操作に不慣れな人にとっては、初期設定やモデル管理で戸惑うことがあります。
Ollamaのインストール方法
以下はMac・Windows共通の基本手順です。
ダウンロードしたファイルを実行してインストールします。
Windows:PowerShellから利用可能
Mac:ターミナルから利用可能
ターミナルまたはPowerShellで以下を実行し、バージョンが表示されればインストール完了です。
ollama --version例:Qwen 7Bモデルを利用する場合
ollama pull qwen:7b対話形式で実行する場合
ollama run qwen:7bAPIサーバーとして常駐させたい場合
ollama serveOllamaを使うためのPCスペック
Ollamaはローカルでモデルを実行するため、利用するモデルのサイズによって必要なスペックが変わります。
軽量モデル(1B〜7Bクラス)
- メモリ:8GB〜16GB程度
- CPU:4コア以上
- GPU:必須ではない(あると高速化)
中〜大型モデル(13B〜70Bクラス)
- メモリ:32GB以上推奨
- GPU:VRAM 16GB以上推奨(例:RTX 4090なら70Bクラスも動作可能)
ストレージ要件
- モデル1つあたり数GB〜数十GBを消費するため、500GB〜1TB以上のSSDを推奨
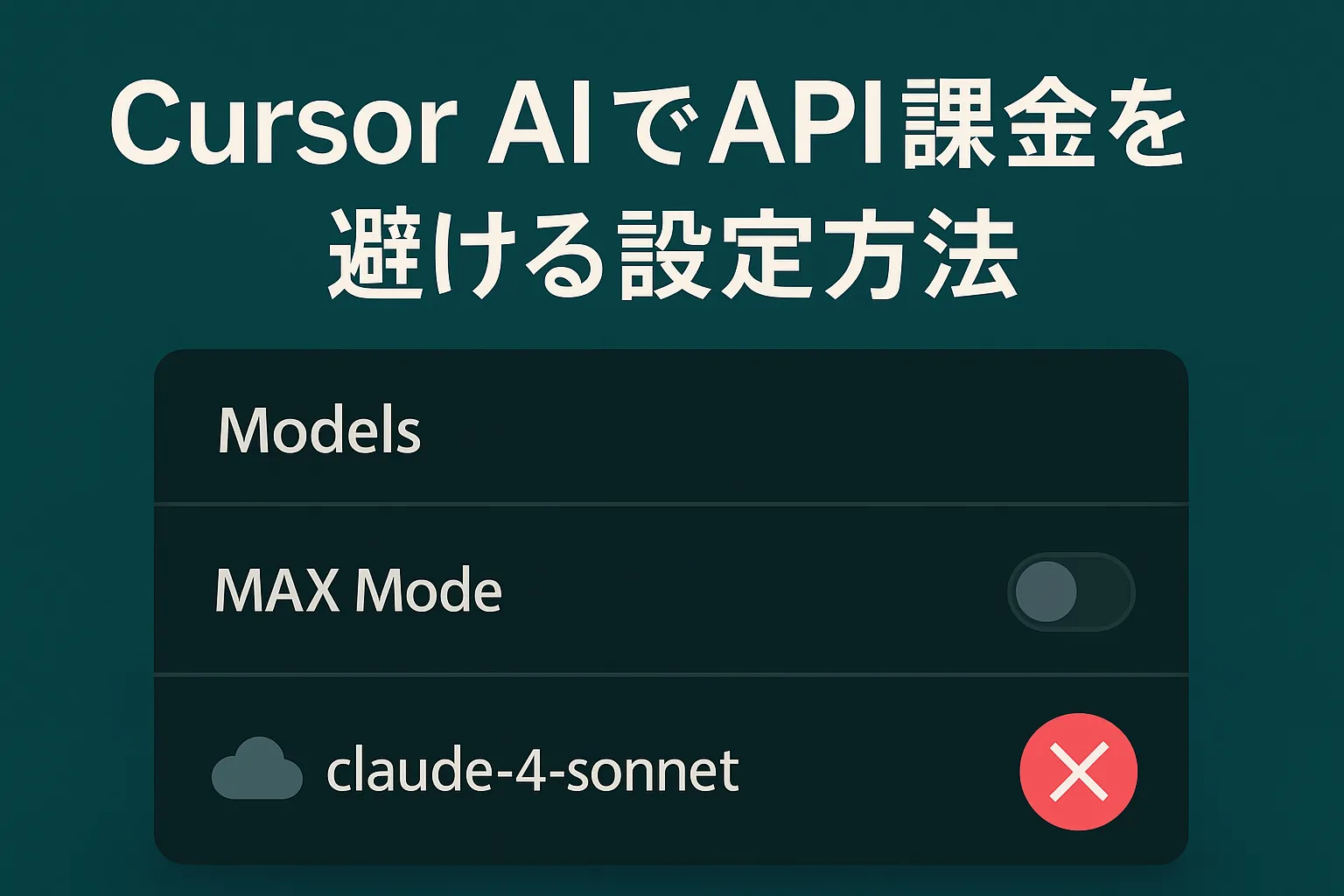
まとめ
Ollamaは、クラウドに依存せずに大規模言語モデルをローカル環境で実行できる強力なツールです。API料金不要、オフライン利用可能、モデル選択の自由度といった大きなメリットがある一方で、PCスペックやストレージ消費、導入のハードルといったデメリットも存在します。
しかし、適切なモデルサイズを選べば、個人PCでも十分に快適に動作させることができます。研究開発、個人学習、セキュリティ要件の厳しい環境など、用途に合わせて柔軟に活用できるのがOllamaの魅力です。